怎么这么难啊
在C语言的基础上继续学习CPP
C++基础知识
C++中函数声明的正确格式:
<返回类型> <函数名>(<参数列表>) [const] [其他限定符];其中 const 可选,后面跟着其他限定符。
extern 的用法
在预编译的过程中,会自动展开头文件。因此定义在头文件的变量就会被多次定义。extern 关键字用于声明一个变量或函数,使其可以在其他文件中访问,而不在当前文件中分配内存。
总结
头文件只做变量的声明,不能做变量的定义
头文件声明变量可以采用extern的方式
变量作用域
与C不同C++多了几种作用域。作用域决定了变量的生命周期和可见性。
- 全局作用域:在函数外部声明变量,一般只在需要的时候才使用,便于代码维护
- 局部作用域:在函数内部、
if语句或for循环内声明的变量。它们只在声明的代码块内被访问。 - 命名空间作用域:在命名空间中声明的变量
- 类作用域:在类内部声明的变量和成员函数。成员变量和成员函数只能通过类的对象访问,而在某些情况(如静态成员)可以直接通过类名访问。
- 块作用域:是局部作用域的一个特例,在函数中额外用大括号
{}来包围的代码块内声明的变量,这些变量只能在代码块内被访问,即使在函数内但是超出代码块也依旧不能访问。
namespace MyNamespace {
int namespaceVar = 10;
}
int main(){
int a = MyNamespace::namespaceVar;
}class MyClass {
public:
int classVar;
}
int main(){
MyClass obj;
obj.classVar = 10;
}void fun() {
{
int a = 1;
}
// 下列代码尝试块外访问块内变量会导致编译错误
// int b = a;
}存储空间
C++通过存储的数据类型、生命周期和作用域来划分。
- 代码区(Code Segment/Text Segment):存储程序执行代码(机器指令)的内存区域,只读,在执行程序时不会改变。
- 全局/静态存储区(Global/Static Storage Area):存储全局变量和静态变量的区域。
- 栈区(Stack Segment):存储局部变量、函数参数、返回地址等的内存区域。栈是后进先出的数据结构,存储函数调用和自动变量。
- 堆区(Heap Segment):由程序员通过动态分配函数(
new或malloc)分配的内存区域。堆的内存分配和释放是手动的,由程序员需要负责管理的内存,避免内存泄漏或野指针等问题。 - 常量区(Constant Area):存储如字符串常量、
const饰的全局变量的区域,这部分内存也是只读的。在C++中,使用双引号括起来的字符串字面量通常存储在常量区。若const修饰的全局变量的值在编译时就已确定,则也可能存储在常量区。
提示
const 修饰的变量是只读的,编译器处理时一般时直接将 const 修饰的变量替换成其初始化的值。默认情况下 const 对象被设定为仅在文件内有效,因此当多个文件中出现了同名的 const 修饰的变量时,其实相当于在不同的文件中定义了不同的变量。比如filea.c和fileb.c都包含了fileh.h文件,而fileh.h中声明了一个 const 修饰的变量var,filea.c和fileb.c中引用该变量其实是不同的,即filea.c中的var与fileb.c中的var地址不相同。
#include <iostream>
#include <cstring> // 用于strlen
// 全局变量,存储在全局/静态存储区
int globalVar = 10;
// 静态变量,也存储在全局/静态存储区,但仅在其声明的文件或函数内部可见
static int staticVar = 20;
void func() {
// 局部变量,存储在栈区
int localVar = 30;
// 静态局部变量,虽然声明在函数内部,但存储在全局/静态存储区,且只在第一次调用时初始化
static int staticLocalVar = 40;
std::cout << "Inside func:" << std::endl;
std::cout << "localVar = " << localVar << std::endl;
std::cout << "staticLocalVar = " << staticLocalVar << std::endl;
// 尝试通过动态内存分配在堆区分配内存
int* heapVar = new int(50);
std::cout << "heapVar = " << *heapVar << std::endl;
// 释放堆区内存(重要:实际使用中不要忘记释放不再使用的堆内存)
delete heapVar;
}
int main() {
// 访问全局变量
std::cout << "Inside main:" << std::endl;
std::cout << "globalVar = " << globalVar << std::endl;
std::cout << "staticVar = " << staticVar << std::endl; // 注意:staticVar在外部不可见(除非在同一个文件中或通过特殊方式)
// 调用函数,展示栈区和堆区的使用
func();
// 字符串常量通常存储在常量区,但直接访问其内存地址并不是标准C++的做法
// 这里我们仅通过指针来展示其存在
const char* strConst = "Hello, World!";
// 注意:不要尝试修改strConst指向的内容,因为它是只读的
std::cout << "strConst = " << strConst << std::endl;
// 尝试获取字符串常量的长度(这不会修改常量区的内容)
std::cout << "Length of strConst = " << strlen(strConst) << std::endl;
return 0;
}Inside main:
globalVar = 10
staticVar = 20
Inside func:
localVar = 30
staticLocalVar = 40
heapVar = 50从下图中可以看出字符串都存储在了常量区。 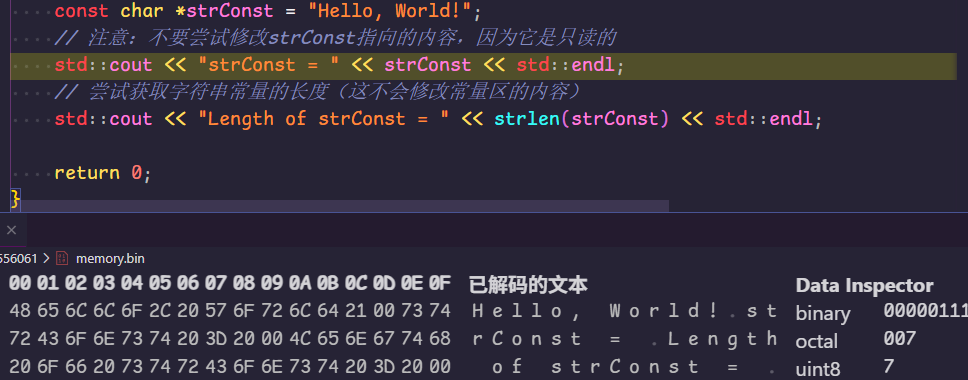
引用
引用可以看作是另一个变量的别名,其用法也较为简单:
int a = 1;
int &b = a;使用符号 & 表示引用,此时变量 a 和 b 的地址相同。此时修改b的值相当于修改a的值,b就是a的别名。
注意
- 必须初始化。在创建引用时,必须指向一个已存在的对象。
- 一旦引用绑定后就不能再修改。
- 不能存在空引用。
左值引用和右值引用
在C++中左值( lvalue )和右值( rvalue )是表达式的两种基本分类,它们决定了表达式的结果在内存中的位置和状态。
左值通常指具有持久状态的对象,有明确的内存地址,可以被多次赋值。左值引用是C++98就有的特性。
右值是临时、没有持久状态的值(临时对象或即将被销毁的对象),通常没有内存地址,或其内存地址在表达式结束后变得无效。右值引用是C++11新增的特性。
int a = 10;
int& b = a; // b是a的左值引用int&& c = 20; // c是整数字面量20的右值引用(但这种情况不常见,通常用于函数参数或返回值)
std::string foo() {
return std::string("Hello, World!"); // 返回的临时字符串是一个右值
}
std::string &&d = foo(); // d是foo()返回的临时字符串的右值引用右值引用的主要用途是作为函数参数(实现移动语义)和返回值(允许链式调用等)。
指针
指针是一种特殊变量。它存储的是另一个变量的地址,而不是该变量本身。通过操作指针可以直接操作内存的数据。nullptr 为空指针,在C++中 0为 false ,非0为 true。
指针存储的是地址,因此指针有两种赋值方式:
- 直接赋值,但是这不常用。
- 利用取地址符号
&获取变量的地址并将其传给指针。取地址符号&获取的地址只能传给指针类型的变量,否则会报错。
int var = 10;
int *ptr = &var;指针本身也是个变量,其存储的是另一个变量的地址,因此计算机也会为指针开辟空间,指针有自己的地址。
再看下面的代码:
int var = 10;
int *ptr1 = &var;
int *ptr2 = ptr1;ptr1是指针,存储的是var的地址,ptr2也是指针,获取了ptr1存储的值也就是var的地址,此时ptr2也指向了var。
指针和引用的区别
指针与引用类似,都能够对其它对象进行间接地访问,但是指针又与引用有许多不同。
- 指针本身就是一个对象,允许对指针赋值和拷贝,在指针地生命周期内可以指向不同的对象,而引用在初始化时就已固定。
- 指针无须初始化。在指针未初始化时其存储的值是不确定的。
万能指针和指向指针的指针
void* 是一种特殊的指针类型,能够存放任意对象的地址。void* 指针存放一个地址,但是该地址存放的数据类型是不知道的。
由于不知道 void* 指向的对象的类型,因此不能利用 void* 直接去操作指向的对象。
void* 主要用来和别的指针进行比较、作为函数的输入或输出,或赋给另一个 void* 指针。
除了万能指针还有指向指针的指针,即**ptr,指向指针的指针存取的是另一个指针的地址。
指针和数组
指针能够通过自增和自减来控制指针存取的地址,通过这种特性,将指针指向一个数组,并让指针自增自减就能起到指针选取不同数组内的元素。
当指针指向数组时,一般指向数组的第一个元素。
//指针可以进行算术运算,如递增(++)和递减(--),
// 这些操作会改变指针所指向的内存地址。但是,这种操作仅限于指向数组元素的指针。
int arr[5] = {1, 2, 3, 4, 5};
int *ptr_arr = arr;
std::cout << "ptr_arr is : " << ptr_arr << std::endl;
int firstElement = *ptr_arr;
std::cout << "firstElement is " << firstElement << std::endl;
// 递增指针
++ptr_arr; // ptr 现在指向 arr[1]
std::cout << "ptr_arr is : " << ptr_arr << std::endl;
// 访问新位置的值
int secondElement = *ptr_arr; // secondElement 等于 2
std::cout << "secondElement is " << secondElement;上面的代码可以看出指针指向数组时,数组不用取地址符号。因为数组名在表达式中会自动转换为指向其首元素的指针,即 arr 是一个指针并指向数组的第一个元素,也即 arr 存取数组第一个元素的地址。在上面的代码中 arr 表示数组的首地址,类型为 int* 等价于
arr = &arr[0];
int *ptr_arr = &arr[0];还有指向整个数组的指针:
int a[5] = {1, 2, 3, 4, 5};
int (*para)[5] = &a;这里的 para 不是指针数组,而是数组指针,这意味着 para 应看作成一个整体,其数据类型为 int*[5]。
因此 para[1] 并不是指代数组 a 的第二个元素,而是偏移了一个 int[5] 的单位后的野指针。 para 本身不是数组,而是指向了一整个数组的指针。
std::cout << (*para)[1] << std::endl;(*para)[1] 才是指代数组 a 的第二个元素,其中 para 在物理意义上存取数组 a 的首地址,但在C++中是存取整个数组的地址。
a 等价于 para[0] , a[0] 等价于 (*para)[0]或 *para , (*para)[1] 等价于 para[0][1] 或 a[1]。
在使用数组指针时,*para[0] 这种写法不够清晰,且容易引起歧义,因此不能这么写,应写成 (*para)[0]。
容易混淆的是para[0][1] 前一个 [] 表示指针位置(指向的地址),后一个 [] 表示数组指针指代数组的元素。
这个在普通的指针上也有类似的情况:
int a = 1;
int *p = &a;p 等价于 p[0],而 p[1] 就是野指针了。
与指针数组对比:
int *para[5];上面的代码意味着 para 数组有5个 int 型指针。
指针数组有n个指针,而数组指针只有一个。
const 关键字
const 修饰的变量为常量,必须初始化且在不能修改。通过 const 提高代码的安全性和可读性。
指针本身也是变量,因此也能够被const修饰。 const 也能修饰函数,一般放在参数列表后面。
const 在声明变量中的位置
const 关键字一般放在变量类型之前:
const int a =10;也可以放在变量类型之后,但比较少见:
int const a = 10;const引用
当有 const 关键词修饰变量时,其引用也必须是 const 修饰的;被引用地变量没有 const 修饰时,其引用也可以用 const 修饰。const 修饰的引用变量类型可以与被引用的变量类型不同,在编译过程中会进行隐式地类型转换。
C++ 允许常量引用绑定到类型不同的右值或临时变量。
double dval = 3.14;
int &rd = dval; // 错误
const int &rt = dval; // 正确
// 相当于
const int temp = dval;
const int &rt = temp;此时 rt 绑定了一个临时对象 temp, 对象 temp 进行类型转换。临时对象常常被称作临时量。
常量指针
指针也能够被 const 修饰,类似于常量对象,在初始化后指向的对象就不能被改变。
要指向常量对象,必须使用常量指针:
const double PI = 3.14;
double * ptr = &PI; // 错误
const double *cptr0 = &PI; // 正确 普通指针
const double *const cptr1 = &PI; // 正确 常量指针cptr0 是指向常量的指针,可以修改指向的对象。cptr1 是指向常量的常量指针,不能修改指向的对象。
const int a = 10;
const int b = 20;
int c = 30;
const int *ptra = &a;
ptra = &b; // 正确
const int *const ptrb = &a;
ptrb = &b; // 错误
const int *ptrc = &c; // 正确
const double *ptrc = &c; // 错误在上面代码中
const int *const ptrb = &a;前一个 const 称作底层 const ,后一个 const 称作顶层 const。
- 顶层
const表示任意的对象是常量,这一点对任何数据类型都适用,如算术类型、类、指针等。 - 底层
const则与指针和引用等复合类型的基本类型部分有关。比较特殊的是,指针类型既可以是顶层const也可以是底层const,这一点和其他类型相比区别明显。
const int *ptrc = &c;
const double *ptrc = &c;C++ 不允许不同类型的指针直接相互赋值,即使都是常量指针,这点与常量引用不同。
只有底层 const 修饰指针,表示该指针不能修改指向对象的值,但是可以修改指向的对象。
constexpr 和常量表达式
constexpr 是 C++11新标准引入的新类型。C++11允许将变量声明为 constexpr 类型,让编译器在编译期间就将该类型的值转换成字面量。 constexpr 修饰的变量也一定是常量。
constexpr 修饰的指针其初始值必须是0或 nullprt ,也可以是某个固定地址中的对象(全局对象等)。
auto 关键词
有时候需要从表达式的返回值赋值给变量,这使得创建的变量要与表达式相同,在工程中要实现这一目标比较不变甚至无法实现,C++11 新标准引入 auto 类型说明符来自动推算变量类型。
但是一条 auto 只能声明一种基本数据类型。
auto a = 0, pi = 3.14;可以在 auto 前加上 const 来指示推断数据类型为常量。
decltype 关键词
decltype(function()) x 通过自动推断函数 function() 的返回值类型,并用它来声明变量 x ,使 x 与 function() 的返回值类型一致。
for 循环
c++中 for 循环多了“范围循环”的形式:
for (a : b){}在C++11的 for 范围循环代码块中,若出现了向量 vector ,在背后会自动调用向量的 begin()/end() 函数,即可以直接写成:
std::vector<int> vec = {1 , 2 ,3};
for(auto c : vec){}等价于:
std::vector<int> vec = {1 , 2 ,3};
for (auto it = vec.begin(); it != vec.end(); ++it) {}向量 vector
向量 vector 是C++标准模板库(STL)中的一种序列容器,能够动态管理可变大小的数组。
定义一个向量:
std:vector<int> numbers; //整数向量
std:vector<std:string> words; //字符串向量向量可以直接增删改查:
push_back():在向量末尾添加一个已有的对象。emplace_back():在向量末尾原地构造一个对象。pop_back():移除向量末尾的元素。insert():在指定位置插入元素。erase():移除指定位置的元素或范围内的元素。clear():移除所有元素。operator[]:通过索引访问元素。at():通过索引访问元素,带边界检查。front():返回指向第一个元素(底层元素)的迭代器。back():返回指向最后一个元素迭代器。size():返回向量中元素的数量。capacity():返回向量目前为止分配的存储容量。empty():检查向量是否为空。begin(): 返回指向向量第一个元素的迭代器,end(): 指向“最后一个元素之后”的位置(不能解引用)。data(): 返回指向第一个元素的指针。find(): 在向量中查找所需的元素。reverse(): 预留内存。
信息
虽然向量可以直接像数组一样操作和赋值,但是向量本身并不是直接指向第一个元素的指针,而是一个对象,因此需要使用 vector.begin() 或 vector.data() 来获取向量第一个元素的迭代器或指针。
for (auto i = vector; i != vector.end(); i++){}
for (auto i = vector.begin(); i != vector.end(); i++){}二维向量:
std::vector<std::vector<int>> matrix(3, std::vector<int>(4, 0));向量内存优化
向量会动态地管理内存,自动调整向量的容量以适应新增或删除的元素,频繁地内存分配可能会影响性能。
- 使用
reverse()来预留内存,减少内存分配地次数。 - 使用
shrink_to_fit()释放向量的多余容量,匹配向量大小。
迭代器
迭代器( Interator ) 是C++标准模板库( STL ) 的一个重要概念。迭代器就像一个指针,但是迭代器只能访问容器内的元素,因此比指针更加安全。
一些具有迭代器的容器(向量等)都会有成员函数 begin() 和 end() 来返回迭代器。
迭代器的运算
*iter:返回迭代器所指元素的引用。iter->mem: 解引用迭代器所指的元素,等价于(*iter).mem++iter: 指向下一个元素--iter: 指向上一个元素iter1 == iter2: 判断两个迭代器是否相等iter1 != iter2: 判断两个迭代器是否不相等
比较类似于指针指向数组。
迭代器失效
由于向量 vector 可以动态增长,但是不能再 for 循环中向 vector 对象添加元素。且任何能够可能改变 vector 对象容量的操作( push_back 、 pop_back 等)都会使该 vector 对象的迭代器失效。
//注意下面逻辑错误,在for循环中push元素导致迭代器失效,也会导致死循环
for(auto it = numbers.begin(); it != numbers.end(); ++it) {
numbers.push_back(1);
}指针类似迭代器用法
指针也是迭代器,在C++11中利用 std::begin() 可以获取数组第一个元素的指针, std::end() 获取数组’最后一个元素之后’ 的指针,与迭代器的 end() 位置相同。
int ia[] = {0,1,2,3,4,5,6,7,8,9};
int * beg = std::begin(ia);
int * end = std::end(ia);
for(auto it = beg; it != end; ++it){
std::cout << *it << " ";
}C 风格字符串
C风格字符串以空字符作为结束( /0 )。在字符串的末尾一般会自动加上空字符( /0 )。
char *str = "hello world!";或
char str[] = "hello world!";此时会在 ! 后面自动加上 /0 。
但是须注意:
char str[] = {'a', 'b', 'c'};虽然这里的 str 也是字符串数组,但是内部没有 /0 ,这就会导致使用查询字符串长度函数 strlen 时,会一致沿着 str 在内存的位置直到找到 /0 才停下来,这也是C风格字符串的漏洞。
类
类就像一个汽车图纸,而对象就是图纸造出来的汽车。实际上类和结构体差不多,类有的结构体也有,它们唯一的区别只有对成员默认访问权限不同:
- 类:默认是
private - 结构体:默认是
piblic
类的定义
类有三种成员,分别是
- 公有成员(public):可以被所有代码访问。
- 私有成员(private):只能被类的成员函数和友元访问。
- 受保护成员(protected):只能被类的成员函数、友元和派生类访问。
友元
友元的关键词为 friend ,能够让一个函数或者类去访问另一个类的私有成员或受保护成员。友元一般定义在类里,在 public private protected 之外。
构造函数
构造函数是与类名相同的特殊成员函数,没有返回类型,在创建对象时自动执行,主要负责对象的初始化。
一般是公有成员,这样外部才能创建该类的对象。若构造函数是私有的,那么只能在类的内部(比如通过静态成员函数)创建对象。
构造函数的具体实现可以放在类外也可以放在类里。
成员变量一般以下划线结尾(如: name_ ),以此区分局部变量。
初始化列表
是一种用于在构造函数中初始化类成员变量的语法,写在构造函数的参数列表和函数体之间,用冒号 : 引导。
某些情况下必须使用初始化列表来初始化变量,比如:
const成员。- 引用成员。
- 对象成员没有默认构造函数。
- 基类构造函数。
explicit成员对象初始化。
因此用初始化列表能解决 99% 的问题。
class Student {
private:
std::string name_;
int age_;
public:
Student(const std::string& name, int age)
: name_(name), age_(age) { // 初始化列表
// 构造函数体(通常可以为空)
}
};等价于:
Student(const std::string& name, int age) {
name_ = name;
age_ = age;
}同时构造函数也可以在外部实现:
Student :: Student(const std::string& name, int age)
: name_(name), age_(age) {
}复杂一点的例子:
#include <iostream>
#include <string>
class Date {
public:
int year, month, day;
Date(int y, int m, int d) : year(y), month(m), day(d) {}
};
class Student {
private:
const int id_; // const 成员变量(必须初始化)
std::string& school_; // 引用类型成员(必须初始化)
std::string name_; // 普通变量(可以在构造函数体赋值,但最好初始化)
Date birthday_; // 对象成员(必须调用构造函数初始化)
public:
// 构造函数使用初始化列表
Student(int id, std::string& school, const std::string& name, const Date& birthday)
: id_(id), // const:必须在初始化列表中初始化
school_(school), // 引用:也必须在初始化列表中初始化
name_(name),
birthday_(birthday) {
std::cout << "Student constructed.\n";
}
void print() {
std::cout << "ID: " << id_ << ", Name: " << name_
<< ", School: " << school_
<< ", Birthday: " << birthday_.year << "-" << birthday_.month << "-" << birthday_.day << "\n";
}
};信息
这里构造函数传递 name 时,是引用传递,可以使得 name 变量直接传递给 name_ 成员,仅一次拷贝。若只是普通传参,则:
- 传参时会复制一份字符串(从实参到形参)。
- 构造函数体内又复制一份字符串(从形参到变量)。 发生了两次拷贝操作,性能损耗较大。
拷贝构造函数和移动构造函数
上述的构造函数是参数化构造函数,除此之外还有:
- 拷贝构造函数:用一个对象去创建另一个对象时。C++
ClassName(const ClassName& other) { _name = other._name; _age = other._age; }; Student s1("Alice", 20); Student s2 = s1; // 触发拷贝构造函数 - 移动构造函数:使用一个临时对象(右值)初始化另一个对象时(避免不必要的深拷贝)。C++临时对象(右值)优先调用移动构造函数初始化
ClassName(ClassName&& other) noexcept { _name = std::move(other._name); _age = std::move(other._age); }; Student s3 = Student("Bob", 21); // 触发移动构造函数s3,避免深度拷贝,提高性能。如果类没有定义移动构造函数,则会退而使用拷贝构造,降低效率。
理论上移动构造函数和直接赋值性能上差不多,在C++17之后,编译器在开启优化的前提下,会强制执行拷贝省略(也称返回值优化 RVO)。
提示
其中 noexcept 表示不会抛出异常,若没有这个关键字,则STL会退而求其次使用拷贝构造。
涉及到移动构造函数,这不得不提C++的Rule of Five(五法则),或
Special Member Functions Generation Rules(特殊成员函数生成规则):
如果在类中定义了以下五个函数:
- 拷贝构造函数(Copy Constructor)
- 拷贝赋值运算符(Copy Assignment)
- 移动构造函数(Move Constructor)
- 移动赋值运算符(Move Assignment)
- 析构函数(Destructor) 则编译器不会自动生成移动构造函数。若需要支持移动语义,除了显式写出移动构造函数,还可以写:
// 放在public区域才能给外界使用
B(B&& other) = default;或
B(B&&) = default; // other可以不用显式
B& operator=(B&&) = default; // 一般还要写全移动赋值运算符拷贝赋值运算符和移动赋值运算符
赋值运算符( operator= )是给已存在的对象赋值,不是创建新的对象,与构造函数不同,因此不能用初始化列表。
这里涉及到运算符重载:
提示
在C++中, operator 关键字用于重载运算符。可以重新定义使用运算符时( +, -, =, ==, []等)该怎么运行。本节涉及到赋值运算符重载( operator= )。
- 拷贝赋值运算符:将一个已有对象的内容拷贝到当前对象。C++
T& operator=(const T& other); - 移动赋值运算符:把一个右值对象的资源移动到当前对象,避免不必要的拷贝。C++
T& operator=(T&& other);
逐字分解:
T&:返回当前对象本身的引用。operator=:赋值运算符重载。const T& other:参数是另一个T类对象的常量引用。T&& other:参数是另一个T类对象的右值引用。
声明赋值运算符时又与声明构造函数不同,由于是对已有的对象进行操作,因此多了一些防止内存泄漏、二次释放以及自我赋值检查的操作。
示例代码:
class MyClass {
public:
MyClass(int val) {
data = new int(val);
}
// 拷贝赋值运算符
MyClass& operator=(const MyClass& other) {
if (this == &other) return *this; // 自我赋值检查
delete data;
data = new int(*other.data); // 深拷贝
return *this;
}
// 移动赋值运算符
MyClass& operator=(MyClass&& other) noexcept {
if (this == &other) return *this; // 自我赋值检查
delete data;
data = other.data;
other.data = nullptr; // 避免析构时重复释放
return *this;
}
~MyClass() {
delete data;
}
private:
int* data;
};在这段代码中,只要是重构赋值运算符的代码中:
- 先进行自我赋值检查,防止赋值给自己导致逻辑出错或资源被提前释放。
- 释放已有的资源,防止内存泄漏。
须注意一点是,移动赋值运算符中,还要让源对象(other)的资源指针设为 nullptr ,避免它在析构时发生二次释放的问题。
提示
指向 nullptr 的指针可以安全地重复 delete 操作,不会导致程序崩溃或行为未定义。
delete 只是释放指针所指向的内存,并没有自动地将指针指向 nullptr ,因此有不需要再使用的指针时,进行 delete 的操作后,还要手动将指针设为 nullptr。
int* p = new int(42);
delete p;
p = nullptr;delete 和 new 只能用于指针。 new 创建的指针必须用 delete , new[] 创建的指针必须用 delete[]。
因为在分配方式上的不同,使用 new[] 时编译器会在内存中“偷偷藏一个额外的数字”来记住数组大小,以便于调用析构函数(如果是对象数组)。delete 只释放一个对象,如果是对 new[] 创建的指针进行 delete 此时可能就会造成内存泄漏或崩溃。new 和 delete 都是针对 堆内存(手动分配) 进行操作的,如果对 栈内存(程序自动分配) 操作可能会出现未定义行为或崩溃。
int* p = new int(10);
delete p;
int* arr = new int[5];
delete[] arr;类继承
类继承允许一个派生类从另一个基类继承属性和行为。通过继承,派生类可以用基类的代码(成员、函数),可以重写现有成员和添加新的成员。派生类继承基类的写法如下:
class Base {
// code
virtual ~Base() = default;
}
class Derived : public Base {
// code
}上式中 public 表示公有继承,它保持基类中 public 和 protected 成员的访问权限不变。
- 若写成
protected:基类的public和protected成员全部变成protected,只能在派生类及其子类中访问。 - 若写成
private:基类的public和protected成员都会变成private,只能在该派生类中访问,子类访问不到。
上述代码的基类中涉及到继承,应该声明一个 虚析构函数:
- 保证通过基类指针/引用删除派生类对象时不会“资源泄漏”。
- 更安全的类层次设计,防止将来踩坑。
虚函数
虚函数允许派生类重新定义基类中的函数,以实现多态性。在类中使用关键字 virtual 来声明函数为虚函数。
基类中定义:
class Base {
public:
virtual void function() {
std::cout << "Base virtual function" << std::endl;
}
virtual void constfunction() const {}
}在派生类(子类)中定义:
class Child : public Base {
publid:
void function() override {
// 重载代码
std::cout << "Child virtual function" << std::endl;
}
void constfunction() override {
// 重载代码
}
}如果基类不写 virtual 那么子类即使写了重名的函数也不会发生重载(覆盖)。
通过基类指针访问重载后的函数,仍然使用被重载后的代码:
MyChild *c = new Child;
MyClass *b = new Class;
MyClass *p = c; // 创建基类指针
p->function; // 使用基类指针访问基类的函数此时会输出 Child virtual function。
信息
类继承基类后,如果基类没有无参数构造函数,则子类应显式调用基类的含参构造函数,为基类进行初始化。
纯虚函数
纯虚函数是在基类中声明但不定义的虚函数,目的是为了让派生类强制实现它。包含了至少一个纯虚函数的类被称为 抽象基类(Abstract Base Class, ABC),在声明的虚函数后面加上 =0 表示纯虚函数。抽象基类不能实例化,抽象基类的目的是作为接口(interface)使用,派生类必须实现其所有纯虚函数,才能实例化对象。
class Shape {
public:
virtual void draw() const = 0; // 纯虚函数
virtual ~Shape() = default;
};
class Circle : public Shape {
public:
void draw() const override {
cout << "Drawing Circle" << endl;
}
};
Shape s; // 抽象类不能被实例化
Circle c; // 派生类实现了纯虚函数,可以实例化
Shape* ptr = &c; // 使用基类指针访问被重载后的函数
ptr->draw();
return 0;最后会输出 Drawing Circle。
拷贝/移动构造与拷贝/移动运算符控制
当基类声明了拷贝/移动构造函数和拷贝/移动赋值运算符时,子类可以直接调用基类已声明的构造和运算符。
拷贝构造和拷贝运算符:
class Base {
public:
Base(std::string str) : name_(str) {
std::cout << "Name:" << name_ <<std::endl;
}
Base(const Base& other) : name_(other.name_) {
std::cout << "Base copy constructor" << std::endl;
}
Base& operator=(const Base& other) {
std::cout << "Base copy assignment" << std::endl;
if (this != &other) {
name_ = other.name_;
}
return *this;
}
virtual ~Base() = default;
protected:
std::string name_;
};
class Derived : public Base {
public:
Derived(std::string str, int value) : Base(str), value_(value) {
std::cout << "Value:" << value_ <<std::endl;
}
Derived(const Derived &other) : Base(other) {
std::cout << "Derived copy constructor" << std::endl;
}
Derived& operator=(const Derived& other) {
std::cout << "Derived copy assignment" << std::endl;
if (this != &other) {
Base::operator=(other); // 显式调用基类的拷贝赋值运算符
value_ = other.value_;
}
return *this;
}
private:
int value_;
};
int main() {
Derived s1 = Derived("Alice", 16);
Derived s2 = s1;
Derived s3("David", 14);
s3 = s1;
return 0;
}此时输出:
Name:Alice
Value:16
Base copy constructor
Derived copy constructor
Name:David
Value:14
Derived copy assignment
Base copy assignment移动构造和移动运算符:
class Base {
public:
Base(std::string str) : name_(str) {
std::cout << "Name:" << name_ << std::endl;
}
Base(Base &&other) noexcept : name_(std::move(other.name_)) {
std::cout << "Base move constructor" << std::endl;
}
Base &operator=(Base &&other) noexcept {
std::cout << "Base move assignment" << std::endl;
if (this != &other) {
name_ = std::move(other.name_);
}
return *this;
}
virtual ~Base() = default;
protected:
std::string name_;
};
class Derived : public Base {
public:
Derived(std::string str, int value) : Base(str), value_(value) {
std::cout << "Value:" << value_ << std::endl;
}
Derived(Derived &&other) noexcept : Base(std::move(other)) {
std::cout << "Derived move constructor" << std::endl;
}
Derived &operator=(Derived &&other) {
std::cout << "Derived move assignment" << std::endl;
if (this != &other) {
Base::operator=(std::move(other)); // 显式调用基类的移动赋值运算符
value_ = other.value_;
}
return *this;
}
private:
int value_;
};
int main() {
Derived s1 = std::move(Derived("Alice", 16));
Derived s2("David", 14);
s2 = std::move(s1);
return 0;
}信息
这里显式调用 std::move 是因为 Base 这个类中没有动态调整内存(使用指针或开辟空间),如果不显式调用 std::move 编译器会触发返回值优化(Return Value Optimization,RVO),直接将s1构造在s2的地址空间里,而不会触发移动构造。
此时输出:
Name:Alice
Value:16
Base move constructor
Derived move constructor
Name:David
Value:14
Derived move assignment
Base move assignment容器与继承
在 C++ 中,对象切片(object slicing) 是指当一个派生类对象赋值给一个基类对象 (而不是指针或引用) 时,只有基类的部分会被拷贝,派生类中新增的成员变量和虚函数行为就会 被“切掉”,这会导致多态失效,这一情况在容器类中比较容易出现。
class Base {
public:
virtual void speak() const {
std::cout << "Base speaking\n";
}
virtual ~Base() = default;
};
class Derived : public Base {
public:
void speak() const override {
std::cout << "Derived speaking\n";
}
};
int main() {
std::vector<Base> vec;
vec.push_back(Derived()); //此时会发生切片
for (const auto& ptr : vec) {
ptr->speak(); // 输出:Base speaking
}
}此时会输出基类声明的虚函数: Base speaking。
此时要解决切片问题,应使用指针或智能指针来解决,即往容器中存储对象指针。则主函数 main 应这样改写:
int main() {
std::vector<Base*> vec;
vec.push_back(new Derived());
for (auto ptr : vec) {
ptr->say(); // 输出:Derived speaking
}
// ❗手动释放内存
for (auto ptr : vec) {
delete ptr;
}
return 0;
}或者使用智能指针:
int main() {
std::vector<std::unique_ptr<Base>> vec;
vec.push_back(std::make_unique<Derived>());
for (const auto& ptr : vec) {
ptr->speak(); // 输出:Derived speaking
}
}智能指针能够避免忘记删除指针,防止内存泄漏。同时由于多个指针都指向同一块地址,容易发生二次释放,因此使用智能指针更安全。最后如果中途抛出异常,则可能不会执行 delete ptr ,依然会造成内存泄露。
提示
智能指针能够自动释放资源,无需手动 delete,且支持转移所有权,符合限带C++的 RAII哲学,还支持异常安全。
| 名称 | 本质 | 用法目的 |
|---|---|---|
unique_ptr<T> | 独占式智能指针(不能拷贝可以移动) | 自动释放内存,避免手动 delete |
shared_ptr<T> | 引用计数式共享智能指针 | 多处共享对象,最后一个释放才释放 |
make_unique<T>() | 安全创建 unique_ptr<T> | 比较推荐的方式,避免裸用 new |
make_shared<T>() | 安全创建 shared_ptr<T> | 在堆上只分配一次内存 |
map
std::map 是C++标准模板库(STL)中的一个关联容器,用于存储键值对(key-value pairs),每个简直都是唯一的,自动排序(一般是升序)。
声明 map
// 键:int 值: std::string
std::map<int,std::string> myMap;
// 键:std::string 值: int
std::map<std::string,double> myMap;初始化 map
std::map<int, std::string> myMap = {
{1, "Apple"},
{2, "Banana"},
{3, "Cherry"}
};常见用法
insert:插入C++myMap.insert(pair<int, string>(4, "Date")); myMap.insert(make_pair(5, "Elderberry")); myMap.insert( {6, "Fig"} );- 运算符
[]操作C++myMap[7] = "Grape"; // 如果键 8 不存在,则会插入键 8 并赋值 myMap[8] = "Honeydew"; at: 键值查询C++string fruit = myMap.at(2); // 获取键为 2 的值 "Banana"find: 元素查询,返回迭代器C++auto it = myMap.find(3);eraser: 删除C++myMap.erase(2); // 传入键值 myMap.erase(it); // 传入迭代器 myMap.erase(myMap.begin(),myMap.find(2)); // 传入范围clear: 删除所有元素C++myMap.clear(); // 删除所有元素size(): 获取容器中元素的数量empty(): 判断容器是否为空count(key): 返回具有指定键元素的数量lower_bound(key): 返回指向第一个不小于键的迭代器upper_bound(key): 返回指向第一个不大于键的迭代器equal_range(key): 返回包含等于指定键元素的范围
自定义排序顺序
struct Compare {
bool operator()(const int& a, const int& b) const {
return a > b; // 降序排序
}
};
map<int, string, Compare> myMapDesc;
myMapDesc[1] = "Apple";
myMapDesc[2] = "Banana";- 本文链接:https://akorin.icu/posts/gccSimpleLearn
- 版权声明:本博客所有文章除特别声明外,均默认采用 CC BY-NC-SA 许可协议。
To Be Continued.

